【基本情報対策】うさぎでもわかるデータベース 第03羽 SQL前編(select文の使い方とその応用)
こんにちは、ももやまです。
今回から3回に分けてSQLの基礎について勉強していきましょう。
初回となる今回は、表を検索するために使うselect文の使い方を、少し応用的なところまで見てきましょう。
なお、重要度は「基本情報で必要かどうか」を基準に設定しています。★の意味は、以下の通りです。
- ★★★:超重要、よく出る
- ★★☆:重要、結構出る
- ★☆☆:余裕があれば見とこうね
目次
1.select文の基本 重要度:★★★
select文では、関係データベース内に保存されているデータ(つまり表)の中から、条件に合致したものを抽出するのが基本です。
まずは、select文の基本的な使い方を見てきましょう。
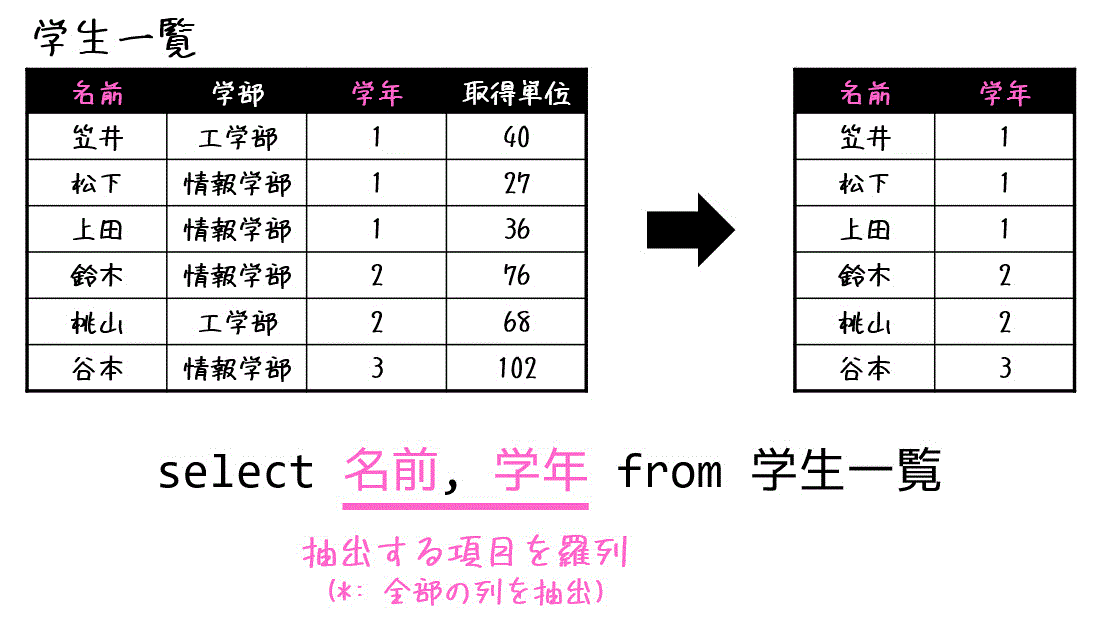
(1) 列の抽出(射影)
射影演算は、表の中から列を取り出す演算でしたね。
select文を用いて列を抽出する場合、列名の部分に抽出したい列名を列挙します。
select 列名 from 表名
例えば下の例の場合、関係「学生一覧」の中から、「名前」、「学年」の列を取り出し、表示します。

また、下のように列名部分に * をつけると、すべての列を抽出します。
select * from 学生一覧
(2) 全く同じデータを表示させない方法 (distinct)
射影演算の厳密な定義は全く同じデータを2回以上出力しません。
しかし、単にselect文で列を指定しただけだと、下のように重複したデータが2回以上出力されてしまう可能性があります。

そこで、下のように列名を列挙する前に distinct をつけることで、重複データを2回以上出力させなくすることができます。
select distinct 列名 from 表名
例えば下の例の場合、工学部と情報工学部が1度だけ出力されます。

(3) 行の抽出(選択)
選択演算は、表の中から行を取り出す演算でしたね。
select文を用いて行を抽出する場合、where 以降の「条件」に一致するものを抽出します。
select 列名 from 表名 where 条件
下の例の場合、関係「学生一覧」の中から、「学年が2であるもの(2年生)」を抽出します。

2.条件文の書き方 重要度:★★★
第2章では、where以降で指定できる条件の書き方について見ていきましょう。
(1) 条件の複数指定 (and, or)
Excelやプログラミングと同じように、複数の条件を and (かつ) や or (または) で指定することができます。
and(2つの条件をともに満たす行を出力)
where 条件1 and 条件2 と書くことで、条件1、条件2を両方とも満たすものを出力することができます。
select 列名 from 表名 where 条件1 and 条件2
下の例の場合、「学年が1(1年生)」と「取得単位が30未満」の両方を満たす行を出力します。

or(2つの条件を片方でも満たす行を出力)
where 条件1 or 条件2 と書くことで、条件1、条件2のうち、片方でも満たすものを出力することができます。
select 列名 from 表名 where 条件1 or 条件2
下の例の場合、「学年が1(1年生)」と「取得単位が70未満」のうち、片方もしくは両方満たす行を出力します。

(2) 条件の否定 (not)
条件の最初に not をつけると、条件を満たさないものを出力することができます。
select 列名 from 表名 where not 条件
下の例の場合、「学部が情報学部ではない」行を出力します。

また、下のように and, or と not と組み合わせて条件を記述することができます。
select * from 学生一覧 where not 学年 = 1 or 取得単位 < 70
ただし、処理順序に気をつけましょう。(not → and → orの順に処理が行われます)
自分で記述をする際には、下のように括弧をつけて計算順序を明確化させておくことをおすすめします。
select * from 学生一覧 where (not 学年 = 1) or (取得単位 < 70)
(3) 範囲の指定 (between)
条件の部分に 列名 between A and B と書くことで、A以上B以下のデータを取り出すことができます。
select 列名 from 表名 where 列名 between A and B
下の例の場合、取得単位が40以上80以下である行を取り出し、出力します。

また、notを付け加えて not between A and B とすることで、値がA以上B以下ではないデータを取り出すことができます。
(4) 指定した項目を抽出 (in)
条件の部分を 列名 in (値1, 値2, …) とすることで、括弧内で指定した値のどれかと一致するデータを出力することができます。
select 列名 from 表名 where 列名 in (値1, 値2, …)
下の例の場合、学部が「文学部」もしくは「経済学部」となっている行を出力します。

また、notを付け加えて not in (値1, 値2, …) とすることで、括弧内で指定した値と一致しないデータを出力することができます。
(5) 指定したパターンを出力 (like)
条件の部分を 列名 like '文字パターン' とすることで、特定の文字パターンと一致(部分一致)する行を出力することができます。
select 列名 from 表名 where 列名 like '文字パターン'
文字パターンの指定では、下の2つのワイルドカードを使うことができます。
% → 任意の文字列 _ → 任意の1文字
下の例の場合、番号が「Aで始まる」行を出力します。

また、notを付け加えて not like '文字パターン' とすることで、特定の文字パターンと一致しない行を出力することができます。
(6) 空からどうかの判定 (ls null) 重要度:★★☆
where 項目名 is null とすることで、項目が空になっているものを出力します。
ただし、実際には is not null のように not を付け加えて「項目が殻になっていない」ものを出力させることが多いです。
例えば、下のSQLの書き方であれば、番号(学生番号のこと)が空になっていない学生を出力することができます。
select 番号, 名前 from 受講一覧 where 番号 is not null
3.結果のソート (order by) 重要度:★★★
条件を指定したあとに order by を付け加えることで出力結果に対して、昇順(asc)もしくは降順(desc)でソートを行うことができます。
select 列名 from 表名 where 条件 order by 列名 ソート方法(asc / desc)
下の例の場合、出力結果を点数の昇順(asc)でソートしたものを改めて出力します。

なお、昇順ソートを行う場合はソート方法を示す asc を省略することができます。そのため、下のSQLでも先程の例と同じ結果を得ることができます。
select * from 受講一覧 order by 点数
2つ以上の列を用いたソート
複数の列を用いてもソートすることができます。ただし、列名ごとに昇順(asc)か降順(desc)を指定する必要があります。(昇順であれば省略OK)
select 列名 from 表名 where 条件 order by 列名1 条件1, 列名2 条件2, …
複数の列を用いる場合、
- まずは1つ目の列の値でソート
- 1つ目の列の値が同じ行のみ、2つ目を確認し、ソート
- さらに同じであれば3つ目……
と行います。
下の例の場合、
- まずは国語の値が昇順になるように並べる
- 国語が同じ値の行に対し、数学の値が降順になるように並べる
の2段階の処理が行われます。

4.様々な集合関数 重要度:★★★
SQLでは集計を行う様々な関数(集合関数と呼びます)を使うことができます。
よく出てくる関数を下に載せておきます。

実際に関数を用いて計算をするときは、下のように 列名 の部分に関数名を入れることで、関数を用いた演算を行えます。
select count(*) from 受験一覧 # 表に格納されている行の数を出力 select avg(点数) from 受験一覧 # 点数の平均値を出力

5.集合関数の応用1(グループごとの出力 group by)重要度:★★★
ここからは、集合関数の応用的な使い方を見てきましょう。
group by 列名 とすることで、指定した列内にあるデータの種類それぞれに対して集合関数を適用することができます。
例えば、group by 学部 とすると、各学部ごとに集合関数を適用することができます。
select 学部, count(*) from 受験一覧 group by 学部 # 学部ごとに行をcountする select 学部, avg(得点) from 受験一覧 group by 学部 # 学部ごとの得点の平均(平均点)を求める

なお、select 学部, count(*) のところを select count(*) のように「学部」を消してしまうと、数字だけが出力されるので要注意です。(どの数字がどの学部と対応しているかがわからなくなる)
条件をつけた絞り込み (having)
グループごとに集合関数を適用するときに、特定の条件を満たしたものだけを出力させたいと思うかもしれません。
このようにグループ化した後に、ある条件を満たしたものだけ出力する際には group by 列名 の後に having 条件 を付け加えます。
select 出力する列名, 集合関数 from 表名 group by 列名 having 条件
(group by に対する条件指定では where は使わないので注意!)
下の例の場合、学部ごとの平均点を求めたあと、70点以上の学部のみを出力しています。

having と where の違い
having と where はどちらも抽出条件を定めるものですね。
しかし、なぜ group by を使ったときにだけ where を使わずに having を使わなければならないのでしょうか。
まず、group by, where, having の3つはそれぞれ呼び出される優先順位があり、下のようになっています。
- where
- group by
- having
つまり、
whereはgroup byの前に実行されるため、グループ化する前の元々のデータに対して絞りこみ条件を指定するhavingはgroup byの後に実行されるため、グループ化後の表に対しての絞りこみ条件を指定する
ことになります。
そのため、グループ化後の表に対して条件を指定する際には、where ではなく having を使う必要があるのです。
逆に言うと、group by を使わなければ having も where も全く同じ働きをします。
そのため、多くの参考書では having は group by に対して使うものと説明されています。
6.集合関数の応用2(入れ子として使用)重要度:★★☆
集合関数の結果を、where や having の条件として使うことができます。
例えば、下のように「受験一覧」から平均点以上をとっている人の行を抽出することができます。

集合関数を絞り込みの条件として使う際には、条件文の中にselect文を入れる必要があることに注意しましょう。
例えば、抽出をする際に 点数 >= avg(点数) のように直接集合関数を用いて比較をすることはできません。
入れ子を用いたSQLについては、SQLの後編(応用)で詳しく説明します。
7.列名の付け替え (as) 重要度:★☆☆
select 列名 from 表名 で列名を指定する際に、as 新列名 とすることで、出力結果の列名を付け替えることができます。(※asは省略OK)
select 列名 as 新列名 from 表名 select 列名 新列名 from 表名 # as を省略
下の例の場合、列名 count(*) を 合計 と付け加えて出力しています。

as は上の例のように、集合関数の名前を付け替える際に使われることが多いです。
なお、複数の列名を指定している場合、付け替えたい列名のみに as 新列名 を付け加えます。(asは省略OK)
下の例の場合、列名1と列名2をそれぞれ新列名1、新列名2と付け替えて出力をします。
select 列名1 as 新列名1, 列名2 as 新列名2, 列名3 from 表名
名前の付け替えは、基本的にめったに出ないので「こんなことができるんだ~」程度の理解度でOKです。
8.複数の表から結果を得る(表の結合)重要度:★★★
2つ以上の表を読み込むことにより、複数の表から結果を得ることができます。
ただし、2つの表をくっつけるための結合条件を書く必要があります。
select 列名 from 表1, 表2 where 結合条件
例えば下の2つの表を結合させる場合、両方の表にある「学部コード」を結合条件として使います。

しかし、whereで結合条件を示す際に 学部コード = 学部コード と書いてしまうと、どっちの表の学部コードを読み込むかがわかりません。
そのため、読み込む表の中に同じ項目がある場合、表名.列名 とすることで、どの表の列名なのかを明らかにします。

なお、列名部分を * としても同じ結果を得ることができます*1。
select * from 学生, 学部 where 学生.学部コード = 学部.学部コード
9.まとめ
今回はSQL前編として、select文の使い方を少し応用的なところまで見ていきました。
最後に、今回出てきた select, from, where, group by, order by, having をどの順番で並べるか確認しましょう。
まず、select文を使う場合、最初に select 表示させる列名 from 使う表名 を必ず列挙する必要があります。その後必要であれば where, group by, having, order by の順に記します。
select 表示させる列名 from 使う表名 where 絞り込む条件 group by グループ化させる列名 having グループ化後の抽出条件 order by ソートに使う列名 (asc/desc)
次回は、表の作成、更新などの select 文以外のSQLを紹介します。
*1:余談ですが、今回は学生の「学部コード」と学部の「学部コード」の列名が同じなので、重複した列名が2回出てきません(自然結合)。しかし、学生の「学部コード」と学部の「コード」のように、重複した列名になっていない場合は重複した列名が2回出てきてしまう(単結合)ので注意が必要です。